|
|
| Line 1: |
Line 1: |
| {{Article
| | This page describes how to set up Funtoo Linux to run Windows 7 Professional 32-bit within a KVM virtual machine. KVM is suitable for running Windows 7 for general desktop application use. It does not provide 3D support, but offers a nice, high-performance virtualization solution for day-to-day productivity applications. It is also very easy to set up. |
| |Author=Drobbins
| |
| |Next in Series=Awk by Example, Part 2
| |
| }}
| |
|
| |
|
| == An intro to the great language with the strange name == | | == Introduction == |
|
| |
|
| === In defense of awk ===
| | KVM is a hardware-accelerated full-machine hypervisor and virtualization solution included as part of kernel 2.6.20 and later. It allows you to create and start hardware-accelerated virtual machines under Linux using the QEMU tools. |
| In this series of articles, I'm going to turn you into a proficient awk coder. I'll admit, awk doesn't have a very pretty or particularly "hip" name, and the GNU version of awk, called gawk, sounds downright weird. Those unfamiliar with the language may hear "awk" and think of a mess of code so backwards and antiquated that it's capable of driving even the most knowledgeable UNIX guru to the brink of insanity (causing him to repeatedly yelp "kill -9!" as he runs for coffee machine).
| |
|
| |
|
| Sure, awk doesn't have a great name. But it is a great language. Awk is geared toward text processing and report generation, yet features many well-designed features that allow for serious programming. And, unlike some languages, awk's syntax is familiar, and borrows some of the best parts of languages like C, python, and bash (although, technically, awk was created before both python and bash). Awk is one of those languages that, once learned, will become a key part of your strategic coding arsenal.
| | [[File:Windows7virt.png|400px|Windows 7 Professional 32-bit running within qemu-kvm]] |
|
| |
|
| === The first awk === | | == KVM Setup == |
| Let's go ahead and start playing around with awk to see how it works. At the command line, enter the following command:
| |
|
| |
|
| <console>$##i## awk '{ print }' /etc/passwd</console>
| | You will need KVM to be set up on the machine that will be running the virtual machine. This can be a local Linux system, or if you are using SPICE (see [[#SPICE (Accelerated Remote Connection)|SPICE]]), a local or remote system. See the SPICE section for tweaks that you will need to make to these instructions if you plan to run Windows 7 on a Funtoo Linux system that you will connect to remotely. |
|
| |
|
| You should see the contents of your /etc/passwd file appear before your eyes. Now, for an explanation of what awk did. When we called awk, we specified /etc/passwd as our input file. When we executed awk, it evaluated the print command for each line in /etc/passwd, in order. All output is sent to stdout, and we get a result identical to catting /etc/passwd.
| | Follow these steps for the system that will be running the virtual machine. |
|
| |
|
| Now, for an explanation of the { print } code block. In awk, curly braces are used to group blocks of code together, similar to C. Inside our block of code, we have a single print command. In awk, when a print command appears by itself, the full contents of the current line are printed.
| | If you are using an automatically-built kernel, it is likely that kernel support for KVM is already available. |
|
| |
|
| Here is another awk example that does exactly the same thing:
| | If you build your kernel from scratch, please see [[KVM|the KVM page]] for detailed instructions on how to enable KVM. These instructions also cover the process of emerging qemu, which is also necessary. [[KVM|Do this first, as described on the KVM page]] -- then come back here. |
|
| |
|
| <console>$##i## awk '{ print $0 }' /etc/passwd</console> | | {{fancyimportant|Before using KVM, be sure that your user account is in the <tt>kvm</tt> group so that <tt>qemu</tt> can access <tt>/dev/kvm</tt>. You will need to use a command such as <tt>vigr</tt> as root to do this, and then log out and log back in for this to take effect.}} |
|
| |
|
| In awk, the $0 variable represents the entire current line, so print and print $0 do exactly the same thing. If you'd like, you can create an awk program that will output data totally unrelated to the input data. Here's an example:
| | Prior to using KVM, modprobe the appropriate accelerated driver for Intel or AMD, as root: |
|
| |
|
| <console>$##i## awk '{ print "" }' /etc/passwd</console> | | <console> |
| | # ##i##modprobe kvm_intel |
| | </console> |
|
| |
|
| Whenever you pass the "" string to the print command, it prints a blank line. If you test this script, you'll find that awk outputs one blank line for every line in your /etc/passwd file. Again, this is because awk executes your script for every line in the input file. Here's another example:
| | == Windows 7 ISO Images == |
|
| |
|
| <console>$##i## awk '{ print "hiya" }' /etc/passwd</console>
| | In this tutorial, we are going to install Windows 7 Professional, 32-bit Edition. Microsoft provides a free download of the ISO DVD image, but this does require a valid license key for installation. You can download Windows 7 Professional, 32 bit at the following location: |
|
| |
|
| Running this script will fill your screen with hiya's. :)
| | http://msft-dnl.digitalrivercontent.net/msvista/pub/X15-65804/X15-65804.iso |
|
| |
|
| === Multiple fields ===
| | {{fancynote|Windows 7 Professional, 32-bit Edition is a free download but requires a valid license key for installation.}} |
| Awk is really good at handling text that has been broken into multiple logical fields, and allows you to effortlessly reference each individual field from inside your awk script. The following script will print out a list of all user accounts on your system:
| |
|
| |
|
| <console>$##i## awk -F":" '{ print $1 }' /etc/passwd</console>
| | In addition, it's highly recommended that you download "VirtIO" drivers produced by Red Hat. These drivers are installed under Windows and significantly improve Windows 7 network and disk performance. You want to download the ISO file (not the ZIP file) at the following location: |
|
| |
|
| Above, when we called awk, we use the -F option to specify ":" as the field separator. When awk processes the print $1 command, it will print out the first field that appears on each line in the input file. Here's another example:
| | http://alt.fedoraproject.org/pub/alt/virtio-win/latest/images/ |
|
| |
|
| <console>$##i## awk -F":" '{ print $1 $3 }' /etc/passwd</console>
| | == Create Raw Disk == |
|
| |
|
| Here's an excerpt of the output from this script:
| | In this tutorial, we are going to create a 30GB raw disk image for Windows 7. Raw disk images offer better performance than the commonly-used QCOW2 format. Do this as a regular user: |
| <pre>
| |
| halt7
| |
| operator11
| |
| root0
| |
| shutdown6
| |
| sync5
| |
| bin1
| |
| ....etc.
| |
| </pre>
| |
| As you can see, awk prints out the first and third fields of the /etc/passwd file, which happen to be the username and uid fields respectively. Now, while the script did work, it's not perfect -- there aren't any spaces between the two output fields! If you're used to programming in bash or python, you may have expected the print $1 $3 command to insert a space between the two fields. However, when two strings appear next to each other in an awk program, awk concatenates them without adding an intermediate space. The following command will insert a space between both fields:
| |
|
| |
|
| <console>$##i## awk -F":" '{ print $1 " " $3 }' /etc/passwd</console> | | <console> |
| | $ ##i##cd |
| | $ ##i##qemu-img create -f raw win7.img 30G |
| | </console> |
|
| |
|
| When you call print this way, it'll concatenate $1, " ", and $3, creating readable output. Of course, we can also insert some text labels if needed:
| | We now have an empty virtual disk image called <tt>win7.img</tt> in our home directory. |
|
| |
|
| <console>$##i## awk -F":" '{ print "username: " $1 "\t\tuid:" $3 }' /etc/passwd</console>
| | == QEMU script == |
|
| |
|
| This will cause the output to be:
| | Now, we'll create the following script to start our virtual machine and begin Windows 7 installation. Note that this script assumes that the two ISO files downloaded earlier were placed in the user's <tt>Downloads</tt> directory. Adjust paths as necessary if that is not the case. Also be sure to adjust the following parts of the script: |
| <pre> | |
| username: halt uid:7
| |
| username: operator uid:11
| |
| username: root uid:0
| |
| username: shutdown uid:6
| |
| username: sync uid:5
| |
| username: bin uid:1
| |
| ....etc.
| |
| </pre> | |
|
| |
|
| === External Scripts ===
| | * Adjust the name of <tt>VIRTIMG</tt> to match the exact name of the VirtIO ISO image you downloaded earlier |
| Passing your scripts to awk as a command line argument can be very handy for small one-liners, but when it comes to complex, multi-line programs, you'll definitely want to compose your script in an external file. Awk can then be told to source this script file by passing it the -f option:
| | * Adjust the <tt>smp</tt> option to use the number of CPU cores and threads (if your system has hyperthreading) of your Linux system's CPU. |
|
| |
|
| <console>$##i## awk -f myscript.awk myfile.in </console> | | Use your favorite text editor to create the following script. Name it something like <tt>vm.sh</tt>: |
|
| |
|
| Putting your scripts in their own text files also allows you to take advantage of additional awk features. For example, this multi-line script does the same thing as one of our earlier one-liners, printing out the first field of each line in /etc/passwd:
| | <syntaxhighlight lang="bash"> |
| <pre>
| | #!/bin/sh |
| BEGIN {
| | export QEMU_AUDIO_DRV=alsa |
| FS=":"
| | DISKIMG=~/win7.img |
| } | | WIN7IMG=~/Downloads/X15-65804.iso |
| { print $1 } | | VIRTIMG=~/Downloads/virtio-win-0.1-74.iso |
| </pre> | | qemu-system-x86_64 --enable-kvm -drive file=${DISKIMG},if=virtio -m 2048 \ |
| The difference between these two methods has to do with how we set the field separator. In this script, the field separator is specified within the code itself (by setting the FS variable), while our previous example set FS by passing the -F":" option to awk on the command line. It's generally best to set the field separator inside the script itself, simply because it means you have one less command line argument to remember to type. We'll cover the FS variable in more detail later in this article.
| | -net nic,model=virtio -net user -cdrom ${WIN7IMG} \ |
| | -drive file=${VIRTIMG},index=3,media=cdrom \ |
| | -rtc base=localtime,clock=host -smp cores=2,threads=4 \ |
| | -usbdevice tablet -soundhw ac97 -cpu host -vga vmware |
| | </syntaxhighlight> |
|
| |
|
| It is also possible to make the script directly executable, by placing a "#!/usr/bin/awk -f" at the top of the file, as follows:
| | Now, make the script executable: |
| <pre>
| |
| #!/usr/bin/awk -f
| |
| BEGIN {
| |
| FS=":"
| |
| }
| |
| { print $1 }
| |
| </pre>
| |
| Next, the script must be made executable by setting the script file's execute bit:
| |
|
| |
|
| <console>$##i## chmod +x myscript.awk</console> | | <console> |
| | $ ##i##chmod +x vm.sh |
| | </console> |
|
| |
|
| Now, you should be able to execute the script as follows:
| | Here is a brief summary of what the script does. It starts the <tt>qemu-kvm</tt> program and instructs it to use KVM to accelerate virtualization. The display will be shown locally, in a window. If you are using the SPICE method, described later in this document, no window will appear, and you will be able to connect remotely to your running virtual machine. |
|
| |
|
| <console>$##i## ./myscript.awk myfile.in</console>
| | The system disk is the 30GB raw image you created, and we tell QEMU to use "virtio" mode for this disk, as well as "virtio" for network access. This will require that we install special drivers during installation to access the disk and enable networking, but will give us better performance. |
|
| |
|
| === The BEGIN and END blocks ===
| | To assist us in installing the VirtIO drivers, we have configured the system with two DVD drives -- the first holds the Windows 7 installation media, and the second contains the VirtIO driver ISO that we will need to access during Windows 7 installation. |
| Normally, awk executes each block of your script's code once for each input line. However, there are many programming situations where you may need to execute initialization code before awk begins processing the text from the input file. For such situations, awk allows you to define a BEGIN block. We used a BEGIN block in the previous example. Because the BEGIN block is evaluated before awk starts processing the input file, it's an excellent place to initialize the FS (field separator) variable, print a heading, or initialize other global variables that you'll reference later in the program.
| |
|
| |
|
| Awk also provides another special block, called the END block. Awk executes this block after all lines in the input file have been processed. Typically, the END block is used to perform final calculations or print summaries that should appear at the end of the output stream.
| | The <tt>-usbdevice tablet</tt> option will cause our mouse and keyboard interaction with our virtual environment to be intuitive and easy to use. |
|
| |
|
| === Regular expressions and blocks ===
| | {{fancyimportant|1= |
| Awk allows the use of regular expressions to selectively execute an individual block of code, depending on whether or not the regular expression matches the current line. Here's an example script that outputs only those lines that contain the character sequence foo:
| | For optimal performance, adjust the script so that the <tt>-smp</tt> option specifies the exact number of cores and threads on your system -- on non-HyperThreading systems (AMD and some Intel), simply remove the <tt>,threads=X</tt> option entirely and just specify cores. Also ensure that the <tt>-m</tt> option provides enough RAM for Windows 7, without eating up all your system's RAM. On a 4GB Linux system, use <tt>1536</tt>. For an 8GB system, <tt>2048</tt> is safe.}} |
|
| |
|
| <pre>/foo/ { print }</pre> | | == SPICE (Accelerated Remote Connection) == |
| | SPICE is a new technology that has been incorporated into QEMU, which allows the virtual machine to run on one system, and allows you to use <code>spicec</code>, the SPICE client, to connect to your remote virtual machine. In real-world use, you can run a SPICE server (via QEMU) and client on the same machine if you like, or have them on the same local area network, or have server and client connect over an Internet connection. Here are some important facts about SPICE: |
| | * SPICE provides accelerated, optimized video updates over the network, similar to VNC |
| | * QEMU can be configured to run a SPICE server, which you can connect to via <code>spicec</code>, the SPICE client. The SPICE client renders to a local window on your system. |
| | * SPICE allows easy copying and pasting across operating systems -- for example, you can copy something in GNOME, paste it into the <code>spicec</code> window and have it appear on your Windows 7 system. |
|
| |
|
| Of course, you can use more complicated regular expressions. Here's a script that will print only lines that contain a floating point number:
| | === SPICE Setup === |
| | To set up SPICE, you need to perform the following changes to the "standard" steps described in this document: |
| | # Emerge QEMU with the <code>spice</code> USE variable on the system that will be running the Windows 7 virtual machine. |
| | # Emerge <code>spice</code> on the system that you will be using to connect to your remote Windows 7 virtual machine. |
| | # In the <code>vm.sh</code> script, remove the existing <code>-vga vmware</code> <code>qemu-kvm</code> option, and add these options: <code>-vga qxl -device virtio-serial-pci -spice port=5900,password=mypass -device virtserialport,chardev=spicechannel0,name=com.redhat.spice.0 -chardev spicevmc,id=spicechannel0,name=vdagent</code> |
| | # Run <code>vm.sh</code> as described in the next section on your remote server (your Windows 7 system will now boot, but you can't see the virtual machine display) and then connect to it by running the following command on your local system: |
| | <console> |
| | # ##i##spicec -h remotehost -p 5900 -w mypass |
| | </console> |
| | The SPICE client window will appear locally and allow you to interact with your Windows 7 system. |
|
| |
|
| <pre>/[0-9]+\.[0-9]*/ { print }</pre>
| | == Starting Windows 7 Installation == |
|
| |
|
| === Expressions and blocks ===
| | Now, it's time to start Windows 7 installation. Run <tt>vm.sh</tt> as follows: |
| There are many other ways to selectively execute a block of code. We can place any kind of boolean expression before a code block to control when a particular block is executed. Awk will execute a code block only if the preceding boolean expression evaluates to true. The following example script will output the third field of all lines that have a first field equal to fred. If the first field of the current line is not equal to fred, awk will continue processing the file and will not execute the print statement for the current line:
| |
|
| |
|
| <pre>$1 == "fred" { print $3 }</pre> | | <console> |
| | $ ##i##./vm.sh |
| | </console> |
|
| |
|
| Awk offers a full selection of comparison operators, including the usual "==", "<", ">", "<=", ">=", and "!=". In addition, awk provides the "~" and "!~" operators, which mean "matches" and "does not match". They're used by specifying a variable on the left side of the operator, and a regular expression on the right side. Here's an example that will print only the third field on the line if the fifth field on the same line contains the character sequence root:
| | Windows 7 installation will begin. During the installation process, you will need to enter a valid license key, and also load ''both'' VirtIO drivers from Red Hat when prompted (Browse to the second DVD, then win7 directory, then x86). |
|
| |
|
| <pre>$5 ~ /root/ { print $3 }</pre>
| | After some time, Windows 7 installation will complete. You will be able to perform Windows Update, as by default, you will have network access if your host Linux system has network access. |
|
| |
|
| === Conditional statements ===
| | Enjoy your virtualized Windows 7 system! |
| Awk also offers very nice C-like if statements. If you'd like, you could rewrite the previous script using an if statement:
| |
| <pre>
| |
| {
| |
| if ( $5 ~ /root/ ) {
| |
| print $3
| |
| }
| |
| }
| |
| </pre>
| |
| Both scripts function identically. In the first example, the boolean expression is placed outside the block, while in the second example, the block is executed for every input line, and we selectively perform the print command by using an if statement. Both methods are available, and you can choose the one that best meshes with the other parts of your script.
| |
|
| |
|
| Here's a more complicated example of an awk if statement. As you can see, even with complex, nested conditionals, if statements look identical to their C counterparts:
| | [[Category:Tutorial]] |
| <pre>
| | [[Category:First Steps]] |
| {
| | [[Category:Virtualization]] |
| if ( $1 == "foo" ) {
| | [[Category:KVM]] |
| if ( $2 == "foo" ) {
| | [[Category:Official Documentation]] |
| print "uno"
| |
| } else {
| |
| print "one"
| |
| }
| |
| } else if ($1 == "bar" ) {
| |
| print "two"
| |
| } else {
| |
| print "three"
| |
| }
| |
| }
| |
| </pre>
| |
| Using if statements, we can also transform this code:
| |
| <pre>
| |
| ! /matchme/ { print $1 $3 $4 }
| |
| </pre>
| |
| to this:
| |
| <pre>
| |
| {
| |
| if ( $0 !~ /matchme/ ) {
| |
| print $1 $3 $4
| |
| }
| |
| }
| |
| </pre>
| |
| Both scripts will output only those lines that don't contain a matchme character sequence. Again, you can choose the method that works best for your code. They both do the same thing.
| |
| | |
| Awk also allows the use of boolean operators "||" (for "logical or") and "&&"(for "logical and") to allow the creation of more complex boolean expressions:
| |
| <pre>
| |
| ( $1 == "foo" ) && ( $2 == "bar" ) { print }
| |
| </pre>
| |
| This example will print only those lines where field one equals foo and field two equals bar.
| |
| | |
| === Numeric variables! ===
| |
| So far, we've either printed strings, the entire line, or specific fields. However, awk also allows us to perform both integer and floating point math. Using mathematical expressions, it's very easy to write a script that counts the number of blank lines in a file. Here's one that does just that:
| |
| <pre>
| |
| BEGIN { x=0 }
| |
| /^$/ { x=x+1 }
| |
| END { print "I found " x " blank lines. :)" }
| |
| </pre>
| |
| In the BEGIN block, we initialize our integer variable x to zero. Then, each time awk encounters a blank line, awk will execute the x=x+1 statement, incrementing x. After all the lines have been processed, the END block will execute, and awk will print out a final summary, specifying the number of blank lines it found.
| |
| | |
| === Stringy variables ===
| |
| One of the neat things about awk variables is that they are "simple and stringy." I consider awk variables "stringy" because all awk variables are stored internally as strings. At the same time, awk variables are "simple" because you can perform mathematical operations on a variable, and as long as it contains a valid numeric string, awk automatically takes care of the string-to-number conversion steps. To see what I mean, check out this example:
| |
| <pre>
| |
| x="1.01"
| |
| # We just set x to contain the *string* "1.01"
| |
| x=x+1
| |
| # We just added one to a *string*
| |
| print x
| |
| # Incidentally, these are comments :)
| |
| </pre>
| |
| Awk will output:
| |
| <pre>
| |
| 2.01
| |
| </pre>
| |
| Interesting! Although we assigned the string value 1.01 to the variable x, we were still able to add one to it. We wouldn't be able to do this in bash or python. First of all, bash doesn't support floating point arithmetic. And, while bash has "stringy" variables, they aren't "simple"; to perform any mathematical operations, bash requires that we enclose our math in an ugly $( ) construct. If we were using python, we would have to explicitly convert our 1.01 string to a floating point value before performing any arithmetic on it. While this isn't difficult, it's still an additional step. With awk, it's all automatic, and that makes our code nice and clean. If we wanted to square and add one to the first field in each input line, we would use this script:
| |
| <pre>
| |
| { print ($1^2)+1 }
| |
| </pre>
| |
| If you do a little experimenting, you'll find that if a particular variable doesn't contain a valid number, awk will treat that variable as a numerical zero when it evaluates your mathematical expression.
| |
| | |
| === Lots of operators ===
| |
| Another nice thing about awk is its full complement of mathematical operators. In addition to standard addition, subtraction, multiplication, and division, awk allows us to use the previously demonstrated exponent operator "^", the modulo (remainder) operator "%", and a bunch of other handy assignment operators borrowed from C.
| |
| | |
| These include pre- and post-increment/decrement ( i++, --foo ), add/sub/mult/div assign operators ( a+=3, b*=2, c/=2.2, d-=6.2 ). But that's not all -- we also get handy modulo/exponent assign ops as well ( a^=2, b%=4 ).
| |
| | |
| === Field separators ===
| |
| Awk has its own complement of special variables. Some of them allow you to fine-tune how awk functions, while others can be read to glean valuable information about the input. We've already touched on one of these special variables, FS. As mentioned earlier, this variable allows you to set the character sequence that awk expects to find between fields. When we were using /etc/passwd as input, FS was set to ":". While this did the trick, FS allows us even more flexibility.
| |
| | |
| The FS value is not limited to a single character; it can also be set to a regular expression, specifying a character pattern of any length. If you're processing fields separated by one or more tabs, you'll want to set FS like so:
| |
| <pre>
| |
| FS="\t+"
| |
| </pre>
| |
| Above, we use the special "+" regular expression character, which means "one or more of the previous character".
| |
| | |
| If your fields are separated by whitespace (one or more spaces or tabs), you may be tempted to set FS to the following regular expression:
| |
| <pre>
| |
| FS="[[:space:]]+"
| |
| </pre>
| |
| While this assignment will do the trick, it's not necessary. Why? Because by default, FS is set to a single space character, which awk interprets to mean "one or more spaces or tabs." In this particular example, the default FS setting was exactly what you wanted in the first place!
| |
| | |
| Complex regular expressions are no problem. Even if your records are separated by the word "foo," followed by three digits, the following regular expression will allow your data to be parsed properly:
| |
| <pre>
| |
| FS="foo[0-9][0-9][0-9]"
| |
| </pre>
| |
| | |
| === Number of fields ===
| |
| The next two variables we're going to cover are not normally intended to be written to, but are normally read and used to gain useful information about the input. The first is the NF variable, also called the "number of fields" variable. Awk will automatically set this variable to the number of fields in the current record. You can use the NF variable to display only certain input lines:
| |
| <pre>
| |
| NF == 3 { print "this particular record has three fields: " $0 }
| |
| </pre>
| |
| Of course, you can also use the NF variable in conditional statements, as follows:
| |
| <pre>
| |
| {
| |
| if ( NF > 2 ) {
| |
| print $1 " " $2 ":" $3
| |
| }
| |
| }
| |
| </pre>
| |
| | |
| === Record number ===
| |
| The record number (NR) is another handy variable. It will always contain the number of the current record (awk counts the first record as record number 1). Up until now, we've been dealing with input files that contain one record per line. For these situations, NR will also tell you the current line number. However, when we start to process multi-line records later in the series, this will no longer be the case, so be careful! NR can be used like the NF variable to print only certain lines of the input:
| |
| <pre>
| |
| (NR < 10 ) || (NR > 100) { print "We are on record number 1-9 or 101+" }
| |
| </pre>
| |
| <pre>
| |
| {
| |
| #skip header
| |
| if ( NR > 10 ) {
| |
| print "ok, now for the real information!"
| |
| }
| |
| }
| |
| </pre>
| |
| Awk provides additional variables that can be used for a variety of purposes. We'll cover more of these variables in later articles.
| |
| | |
| We've come to the end of our initial exploration of awk. As the series continues, I'll demonstrate more advanced awk functionality, and we'll end the series with a real-world awk application.
| |
| | |
| == Resources ==
| |
| | |
| * Read Daniel's other awk articles on Funtoo: Awk By Example, [[Awk by example, Part2 |Part 2]] and [[Awk by example, Part3 |Part 3]].
| |
| * If you'd like a good old-fashioned book, [http://www.oreilly.com/catalog/sed2/ O'Reilly's sed & awk, 2nd Edition] is a wonderful choice.
| |
| * Be sure to check out the [http://www.faqs.org/faqs/computer-lang/awk/faq/ comp.lang.awk FAQ]. It also contains lots of additional awk links.
| |
| * Patrick Hartigan's [http://sparky.rice.edu/~hartigan/awk.html awk tutorial] is packed with handy awk scripts.
| |
| * [http://www.tasoft.com/tawk.html Thompson's TAWK Compiler] compiles awk scripts into fast binary executables. Versions are available for Windows, OS/2, DOS, and UNIX.
| |
| * [http://www.gnu.org/software/gawk/manual/gawk.html The GNU Awk User's Guide] is available for online reference.
| |
| * [http://www.folkstalk.com/2011/12/good-examples-of-awk-command-in-unix.html Awk Command] daily useful examples.
| |
| [[Category:Linux Core Concepts]] | |
| [[Category:Articles]] | | [[Category:Articles]] |
| {{ArticleFooter}}
| |
This page describes how to set up Funtoo Linux to run Windows 7 Professional 32-bit within a KVM virtual machine. KVM is suitable for running Windows 7 for general desktop application use. It does not provide 3D support, but offers a nice, high-performance virtualization solution for day-to-day productivity applications. It is also very easy to set up.
Introduction
KVM is a hardware-accelerated full-machine hypervisor and virtualization solution included as part of kernel 2.6.20 and later. It allows you to create and start hardware-accelerated virtual machines under Linux using the QEMU tools.
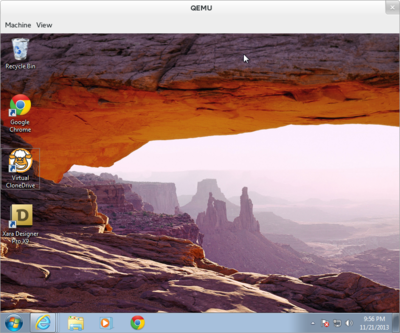
KVM Setup
You will need KVM to be set up on the machine that will be running the virtual machine. This can be a local Linux system, or if you are using SPICE (see SPICE), a local or remote system. See the SPICE section for tweaks that you will need to make to these instructions if you plan to run Windows 7 on a Funtoo Linux system that you will connect to remotely.
Follow these steps for the system that will be running the virtual machine.
If you are using an automatically-built kernel, it is likely that kernel support for KVM is already available.
If you build your kernel from scratch, please see the KVM page for detailed instructions on how to enable KVM. These instructions also cover the process of emerging qemu, which is also necessary. Do this first, as described on the KVM page -- then come back here.
Important
Before using KVM, be sure that your user account is in the kvm group so that qemu can access /dev/kvm. You will need to use a command such as vigr as root to do this, and then log out and log back in for this to take effect.
Prior to using KVM, modprobe the appropriate accelerated driver for Intel or AMD, as root:
root # modprobe kvm_intel
Windows 7 ISO Images
In this tutorial, we are going to install Windows 7 Professional, 32-bit Edition. Microsoft provides a free download of the ISO DVD image, but this does require a valid license key for installation. You can download Windows 7 Professional, 32 bit at the following location:
http://msft-dnl.digitalrivercontent.net/msvista/pub/X15-65804/X15-65804.iso
Note
Windows 7 Professional, 32-bit Edition is a free download but requires a valid license key for installation.
In addition, it's highly recommended that you download "VirtIO" drivers produced by Red Hat. These drivers are installed under Windows and significantly improve Windows 7 network and disk performance. You want to download the ISO file (not the ZIP file) at the following location:
http://alt.fedoraproject.org/pub/alt/virtio-win/latest/images/
Create Raw Disk
In this tutorial, we are going to create a 30GB raw disk image for Windows 7. Raw disk images offer better performance than the commonly-used QCOW2 format. Do this as a regular user:
user $ cd
user $ qemu-img create -f raw win7.img 30G
We now have an empty virtual disk image called win7.img in our home directory.
QEMU script
Now, we'll create the following script to start our virtual machine and begin Windows 7 installation. Note that this script assumes that the two ISO files downloaded earlier were placed in the user's Downloads directory. Adjust paths as necessary if that is not the case. Also be sure to adjust the following parts of the script:
- Adjust the name of VIRTIMG to match the exact name of the VirtIO ISO image you downloaded earlier
- Adjust the smp option to use the number of CPU cores and threads (if your system has hyperthreading) of your Linux system's CPU.
Use your favorite text editor to create the following script. Name it something like vm.sh:
#!/bin/sh
export QEMU_AUDIO_DRV=alsa
DISKIMG=~/win7.img
WIN7IMG=~/Downloads/X15-65804.iso
VIRTIMG=~/Downloads/virtio-win-0.1-74.iso
qemu-system-x86_64 --enable-kvm -drive file=${DISKIMG},if=virtio -m 2048 \
-net nic,model=virtio -net user -cdrom ${WIN7IMG} \
-drive file=${VIRTIMG},index=3,media=cdrom \
-rtc base=localtime,clock=host -smp cores=2,threads=4 \
-usbdevice tablet -soundhw ac97 -cpu host -vga vmware
Now, make the script executable:
user $ chmod +x vm.sh
Here is a brief summary of what the script does. It starts the qemu-kvm program and instructs it to use KVM to accelerate virtualization. The display will be shown locally, in a window. If you are using the SPICE method, described later in this document, no window will appear, and you will be able to connect remotely to your running virtual machine.
The system disk is the 30GB raw image you created, and we tell QEMU to use "virtio" mode for this disk, as well as "virtio" for network access. This will require that we install special drivers during installation to access the disk and enable networking, but will give us better performance.
To assist us in installing the VirtIO drivers, we have configured the system with two DVD drives -- the first holds the Windows 7 installation media, and the second contains the VirtIO driver ISO that we will need to access during Windows 7 installation.
The -usbdevice tablet option will cause our mouse and keyboard interaction with our virtual environment to be intuitive and easy to use.
Important
For optimal performance, adjust the script so that the -smp option specifies the exact number of cores and threads on your system -- on non-HyperThreading systems (AMD and some Intel), simply remove the ,threads=X option entirely and just specify cores. Also ensure that the -m option provides enough RAM for Windows 7, without eating up all your system's RAM. On a 4GB Linux system, use 1536. For an 8GB system, 2048 is safe.
SPICE (Accelerated Remote Connection)
SPICE is a new technology that has been incorporated into QEMU, which allows the virtual machine to run on one system, and allows you to use spicec, the SPICE client, to connect to your remote virtual machine. In real-world use, you can run a SPICE server (via QEMU) and client on the same machine if you like, or have them on the same local area network, or have server and client connect over an Internet connection. Here are some important facts about SPICE:
- SPICE provides accelerated, optimized video updates over the network, similar to VNC
- QEMU can be configured to run a SPICE server, which you can connect to via
spicec, the SPICE client. The SPICE client renders to a local window on your system.
- SPICE allows easy copying and pasting across operating systems -- for example, you can copy something in GNOME, paste it into the
spicec window and have it appear on your Windows 7 system.
SPICE Setup
To set up SPICE, you need to perform the following changes to the "standard" steps described in this document:
- Emerge QEMU with the
spice USE variable on the system that will be running the Windows 7 virtual machine.
- Emerge
spice on the system that you will be using to connect to your remote Windows 7 virtual machine.
- In the
vm.sh script, remove the existing -vga vmware qemu-kvm option, and add these options: -vga qxl -device virtio-serial-pci -spice port=5900,password=mypass -device virtserialport,chardev=spicechannel0,name=com.redhat.spice.0 -chardev spicevmc,id=spicechannel0,name=vdagent
- Run
vm.sh as described in the next section on your remote server (your Windows 7 system will now boot, but you can't see the virtual machine display) and then connect to it by running the following command on your local system:
root # spicec -h remotehost -p 5900 -w mypass
The SPICE client window will appear locally and allow you to interact with your Windows 7 system.
Starting Windows 7 Installation
Now, it's time to start Windows 7 installation. Run vm.sh as follows:
user $ ./vm.sh
Windows 7 installation will begin. During the installation process, you will need to enter a valid license key, and also load both VirtIO drivers from Red Hat when prompted (Browse to the second DVD, then win7 directory, then x86).
After some time, Windows 7 installation will complete. You will be able to perform Windows Update, as by default, you will have network access if your host Linux system has network access.
Enjoy your virtualized Windows 7 system!
