Error
Jump to navigation
Jump to search
The revision #1356 of the page named "File:Amd-gseries-platform-diag.jpg" does not exist.
This is usually caused by following an outdated history link to a page that has been deleted. Details can be found in the deletion log.
{kind=link}
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 06:04, April 27, 2014 | 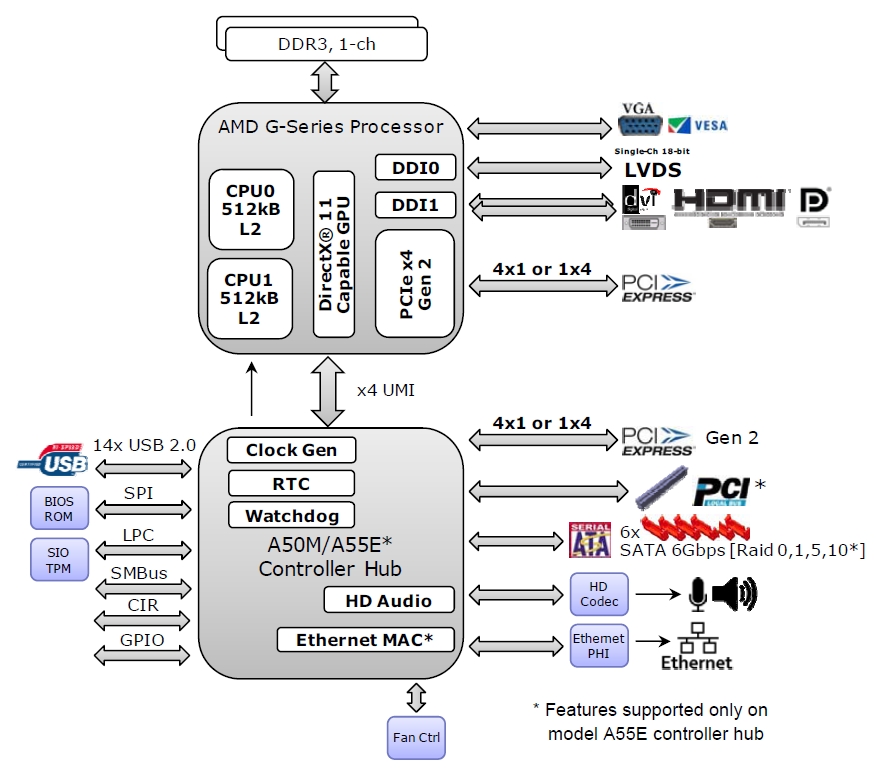 | 883 × 775 (204 KB) | Maintenance script (talk | contribs) | Importing file |
| 05:55, April 27, 2014 | 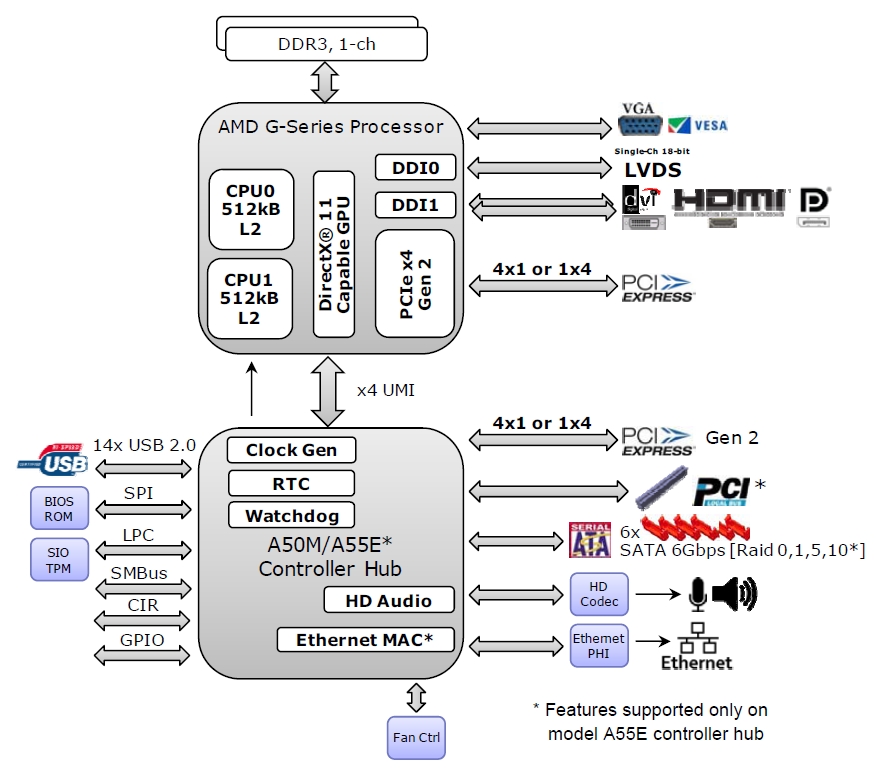 | 883 × 775 (204 KB) | Maintenance script (talk | contribs) | Importing file |
You cannot overwrite this file.
File usage
The following page uses this file:
{kind=link}